
There are a number of previous talks and other posts in various stages of “nearly finished” that I’ll try and sort in the next few weeks/months. They’ll be put in retrospective date order.
Regression Testing: The Bane of the Tester
I was fortunate enough to be invited to the 2nd Midlands Exploratory Workshop on Testing (MEWT) which took place on the 13th September at the wonderful Attenborough Nature Centre.
(You can read more about the background to the MEWT concept and the day’s events on the MEWT blog.)
The theme of this year’s workshop was “Regression Testing”.
I’ve set out my presentation in long form below but if you want the original slides here they are: MEWT – Regression Testing
Initial thoughts
When I first read what the theme of this year’s workshop was I thought “Well, that’s a bit obvious. Surely everyone knows what Regression Testing is?”
It turns out there’s no such thing as a silly question, especially when it comes to testing.
So let me just set out what I understand regression testing to be, because I know already (thanks, Twitter) that there’s a difference of opinion in the room as to what that might be.
Again, I’m not going off what the “dictionary definition” says. I’ve deliberately not looked it up. I must present what I understand it to be, not what I’d like it to be, and certainly not what some other source says it is.
Regression Testing is…
Ensuring what has already been tested, and found to be good, remains so as the software continues to be developed.
Ideally you would re-run all your previous tests every time there is a change.
What’s the problem?
Q: Why is it the “bane of the tester”?
A: There is rarely (if ever) enough resource to cover a full regression test every time it is needed.
Reducing the load
There are some common tactics to reduce the workload…
1. Don’t retest everything.
- Wait until there are enough changes built up to form a release, then test that.
- Reduces effort with minimal risk.
- Only test significant changes.
- How do you determine “significant”?
- Only test those areas likely to have been affected.
- Again, sensible, but how is this determined?
2. Don’t do it all yourself.
- Spread the testing effort out across the team.
- Rerunning tests manually is dull. Rotate the tests. Share the pain.
- Outsource the testing.
- Rerunning tests manually is dull. Let factory testers do it.
- Automate the testing.
- Let the computer do the work. Now you have two problems.
Coverage
Regression Tests are…
- All the tests you have run to check against requirements.
- All the tests you have run to check the fixes are correct.
That’s a lot of tests.
Regression Testing vs Sapient Testing
Regression Testing is the antithesis of Sapient Testing.
- Use sapient testing to explore the way ahead.
- Use regression testing to shore up the road behind.
The one thing to take away from the workshop was that everyone came away with a different idea of what Regression Testing should be and could be than when they started that day. (As I’ve already said.)
I’d say that, on that basis alone, it was a worthwhile exercise.
99-Second Talk: Software Crisis?
As delivered in under 1:39 at TestBash 2.0, Brighton, 22nd March 2013.
[This is from my notes. It probably isn’t what I actually blurted out. Video evidence to follow, probably…]
While thinking about what to talk about today for some reason a term that I had not really encountered since university days came to mind. Has anyone heard of the term Software Crisis?
[One person put their hand up: Michael Bolton IIRC.]
Well there’s a reason for that. It was coined back in 1968 at the NATO Conference on Software Engineering held in Germany. It was (is?) an emotive, provocative term that posited this: with the increase in complexity of software made possible by rapid advances in computing power, how can we ever successfully manage such projects? We can do anything with a computer we can set our minds to. There is no bound to things that are virtual, and whose mechanics are invisible. To paraphrase Fred Brooks, there will never be enough human resources to build (provably) correct software.
-
So, is the term an anachronism?
-
If the term no longer has currency [it seems that way by show of hands hand], are we still in crisis or out of the woods?
-
Are software development methodologies are simply various ways of managing crises?
Why is documentation so hard to write?
I have two weeks left to get all my testing documentation together for a single project (including writing new material, inevitably) before I leave my current job. Fortunately this is the only task I have left to do, there are no other demands on my time, and I’ve time enough to do it. This has given me pause to consider why “documentation” is a dirty word and what approaches might help remedy the negative perception and, more importantly, allow space and time for it actually to be completed.
Some thoughts, then…
- If the documentation is not defined as a project deliverable then–guess what–it will not be delivered.
- As such, you’re relying on sheer good will for it to appear at all which is plainly not realistic. It’s enough just to get the software out in the time available. Anything else will go to the wall.
- Every user claims to want documentation but with no clear indication of the general literacy of the user base. This requires effort to establish before documentation should even be started.
- If resources are taken away to write documentation or the release date is pushed back to accommodate the same, users will clamour for the software instead.
- I can’t stress this one enough: useful documentation seems to take about as much time to produce and get right as the software it describes.
- Any documentation that is produced tends to be either rather sparse or, conversely, detailed to the point of near-uselessness (eg “this is how you use the mouse”). Often an author without clear direction will lurch somewhere between the two extremes, redrafting furiously in an attempt to strike a balance.
- Developers/designers/architects suffer from the illusion that “making the UI intuitive” will preclude the need for documentation. Brave attempts are made towards this but intuition is like common sense: everyone thinks they know what it is, but it’s different for every person.
- The documentation needs testing as well (proofreading, walkthroughs, etc).
- It should be sent for review to the user base, as well as within the project team.
- The very act of writing the documentation means you look at the software from a inherently different angle (often the reverse angle).
- As such, you’ll probably spot things about the software that have never been considered (it’s a rather baroque form of testing). This might necessitate a change to the system, which will in turn need to be reflected in the documentation. This tightly-closed feedback loop really ought to be followed to exhaustion.
Five Misleading Software Testing Concepts
This week I gave a lightning talk about Five Misleading Software Testing Concepts at the STC Meetup in Cambridge. They were:
- Automated Testing
- Quality Assurance
- Best Practices
- Bug Counts
- Code Complete
My cue cards can be found here.
[Edit: 29/03/12] I also gave this talk at the STC Meetup in Birmingham last night. Here’s a blogged response already.
[Edit: 03/04/13] Once again (and for the final time I think) I gave this talk exactly a year later at the inaugural Sheffield Test Gathering on 28th March.
Permit me some self-promotion here:
.@pmberry2007 provoking some lively discussion at the first #shefTest. twitter.com/WhyAyeMac/stat…
— Iain Mc (@WhyAyeMac) March 28, 2013
Some advice on when to, and when not to, use Date Pickers
Using a date picker (or calendar control) as the only way to enter a date of birth (DoB) is a really unhelpful trend in online forms.
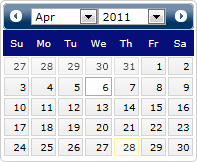
jQuery’s date picker control
I urge UI/UX designers to stop and examine why they do this, and for testers to kick back on this issue.
Here’s why…
Date pickers are great for relative dates, such as when booking leave or travel: the exact date is not necessarily known and might be actively being explored. This is why they’ve been in use for years on holiday websites, for example.
However they are an obstruction when entering absolute dates (known, fixed dates). The most egregious example of this is when entering one’s DoB on a form. This is a value etched on our minds and we’re so used to it that we type it as fast as we’re able, without thought, in the date format appropriate to our locale as well. Attempting to select this from a date picker widget (which unhelpfully tends to default to the current date too) is a serious impediment to ease of use and should be shunned.
A simple text field that accepts a date in the local format–clearly labelled as such, eg dd/mm/yy–is all that’s required. If you insist, add a date picker alongside the field as well, but don’t offer it as the only entry point. (I guarantee no-one will use it anyway.)
If you use a date picker for anything other than a DoB, pay attention to the default date. This should be something sensible such as the current date, the date an event starts on, or whatever is appropriate in the context.
Anything that gets in the way of free and flowing navigation and input by your users will irk them. Collectively a lot of small annoyances like these will add up to a poor user experience, even though any single one of them is only a trivial matter.
Cucumber is inherently compromised
Background
I attended the STC Meetup in Birmingham on Tuesday evening and was struck by a realisation towards the end of Simon Knight‘s lightning talk on the pros and cons (they were mostly cons) of Cucumber. More on this epiphany later…
By happy coincidence I had recently started to look into Cucumber as a concept because our development team on the SAMS Programme here at Nottingham are trying to move towards embracing continuous integration as a methodology. I have read and digested the Cuke4Ninja how-to PDF and it seems, on the surface, to be addressing some of the failings of “traditional” software development. Its main thrust is the use of Gherkin, a form of Structured English, to enable requirements specifications, or derivations thereof, to be put forth in much tighter and more precise terms than are commonly used. Bluntly the idea is that by aiming to reduce ambiguity, better software will result faster. Riding on the coat-tails of this are programming language libraries (Cucumber is by far the dominant one) to make Gherkin statements executable and thus testable in some limited sense.
Criticism
With good timing James Bach (also at the Meetup) had recently weighed in with some strident criticism of the Behaviour-Driven Development (BDD) methodology that Cucumber is a tool for.
Realisation
I realised during Simon’s presentation that Cucumber tries to position itself at the intersection of Analysis, Development and Testing (visualise a Venn diagram of these roles) and is therefore essentially a compromise between all three.
To quote from Cuke4Ninja (page 13 of the PDF):
Cucumber is a functional test automation tool for lean and agile teams. It supports behaviour-driven development, specification by example and agile acceptance testing. You can use it to automate functional validation in a form that is easily readable and understandable to business users, developers and testers. [my emphasis]
The point I raised during the Q&A was that since each group already produces their own form of documentation particular to their viewpoint (Business Analysts write requirements specifications, Developers have their code, Testers produce test plans, etc) how can any documentation possibly sit between all three and not be compromised? Who would author such documentation? Who would own it? And who would realistically countenance adding what would be a fourth layer to the mix when documentation is hard enough to do anyway? It is yet another set of documents to be kept in synch with the true requirements, which are hard enough to ever nail down.
Caution
If BDD is half of what it’s cracked up to be, such an investment might be worthwhile. There are some interesting concepts there and not all are without merit. But it is the nature of people to overstate the worth of something new so we need to exercise caution while at the same time being open to new ideas. I’m reminded once again of Fred Brooks’ paper No Silver Bullet which still stands as an undefeated caveat to the entire software industry 25 years since it was published.
Futher Work
I leave you with these notes I jotted down after the session. Despite the scepticism above, I still intend to do this, though I admit my enthusiasm has been somewhat tempered:
Cucumber/Gherkin
– learn it
– apply it
– report on your experiences
– bask in the warm glow/icy frost of your peers
Watch this space.
Software Testing Alone
Last week I gave a quick standup talk on the subject of Software Testing Alone at the STC Meetup in Nottingham. Slides, which I did not use at the time, are here…
A rare beast: 414 Request-URI Too Long
Just encountered my first 414 error: “Request-URI Too Long”. However I’m surprised it hasn’t happened to me sooner given how many Web 2.0(TM) websites use api calls to other apps via urls. (In other words, daisy-chaining ever longer referring urls into the next url visited.) For example, this is the url even the mighty Google baulked at when I wanted to post a comment on a blog by logging in to one of the main social media services linked to from within the blog page itself (thanks, TypePad).
https://www.blogger.com/openid-login.g?oidrp.identity=http%3A%2F%2Fthese-are-testing-times.blogspot.com%2F&oidrp.return_to=https%3A%2F%2Fwww.typepad.com%2Fsecure%2Fservices%2Fsignin%2Fopenid%3Farchetype.to%3D%252Fsitelogin%253Ffp%253Dc635b981cc45b06c0d2fd7cb720da2c5%2526view_uri%253Dhttp%25253A%25252F%25252Fprofile.typepad.com%25252F%2526service%253Dopenid%2526uri%253Dhttp%25253A%25252F%25252Fmarkhadfield.typepad.com%25252Fthat_gormandizer_man%25252F2009%25252F02%25252Fthetrainlinecom-fail.html%26openid-check%3D1%26archetype.via%3Dblogside%26tos_locale%3Den_US%26portal%3Dtypepad%26archetype.signin_openid%3D1%26oic.time%3D1294411291-e889c028716a401f72b9&oidrp.trust_root=https%3A%2F%2Fwww.typepad.com%2F&oidrp.assoc_handle=&oidrp.sreg.opt=timezone%2Cdob%2Cgender%2Clanguage%2Cpostcode%2Cfullname%2Ccountry&oidrp.sreg.req=nickname%2Cemail
What do you mean you can’t process this? It’s only 844 characters long!
[Edit: 10/01/11]
Further discussion here; 255 characters seems to be the gentlemen’s agreement.
If you can’t unsubscribe from bulk emails, they become spam
Here’s an example of how not to do bulk emails.
Consumer Alerts
This email has been sent to the following email address: xx@xxxxxx.xx.xxYou are receiving this email because you have registered with creditcrunchfixsurvey.co.uk. creditcrunchfixsurvey.co.uk respects your privacy and only sends emails to registered members. Our emails are never sent unsolicited.
If you wish to unsubscribe from our future special offers click here.
http://consumer-alerts.co.uk/public/unsubscribe.jsp?gid=some_randomised_string
Please note that unsubscribe requests must be made from the email account used to register with creditcrunchfixsurvey.co.uk: xx@xxxxxx.xx.xx
To find out more about us and our privacy policy.
http://consumer-alerts.co.uk/re?l=some_other_randomised_string
The unsubscribe link does nothing. The page visited appears to ask a question:
Confirm Unsubscription
Are you sure you would like to unsubscribe from the Group(s):
Consumer Alerts (mailto:info@consumer-alerts.co.uk)
with the following email-address: xx@xxxxxx.xx.xx?
We will send you a confirmation mail of this unsubscription. If you wish to re-subscribe, please reply to this email.
But there is still no mechanism by which you can actually confirm you wish to unsubscribe. Given the wording it looks like there should be a pair of [OK] and [Cancel] buttons but there aren’t. And sure enough, no confirmation email ever appears either.
OK, let’s try visitng their privacy policy page:
No such host.
Thinking laterally and going straight to http://consumer-alerts.co.uk gives no clues about how to unsubscribe either.
OK, a last-ditch attempt. This almost certainly won’t work (if they don’t care about letting people manage the emails they receive from them, how likely is it that they’ll reply to a manual request?):
Please remove xx@xxxxxx.xx.xx from all mailing lists you operate. I have tried to unsubscribe by following the links in the emails but they do not work.
After removing my email address, you should probably fix this problem.
Regards,
Paul
Update 22/09/10:
There is a submit button on the unsubscribe confirmation page, stuck out of sight at the extreme right of the page. I only noticed by looking at the source:
<div class=”submit-row”>
<button name=”unsubscribe” type=”Submit”>- YES -</button>
</div>
Moral: If you do not provide an unsubscribe facility, or make it hard to find/use, then previously-solicited email that you no longer want very quickly becomes unsolicited. Thus, consumer-alerts.co.uk are spammers.